

Parallel Thinking in AI Models

At this week's ML reading group at DeepFlow, we looked at a question that shows up everywhere in agentic systems: how do you get the benefits of parallel reasoning without paying for it in latency?
Most "parallel thinking" approaches improve answers by sampling multiple independent reasoning attempts, but end-to-end latency often gets worse because completion is still gated by the slowest branch—especially when parallelism is fixed and "all-at-once".
The AsyncThink paper proposes a different idea: teach the model to organize its own parallel work—spawning helpers only when useful, merging partial results as they arrive, and stopping early once it has enough.
Why this paper caught our attention
AsyncThink treats a single model's reasoning process as an "agentic organization": an organizer role that can delegate subproblems to worker threads, then merge their results into a final answer. The twist is that the "organization policy" is not hand-designed—it's learned. The paper explicitly argues fixed parallel thinking is limited by (1) slowest-branch latency and (2) lack of adaptivity, and proposes learning an adaptive organization policy instead.
This relates closely to what DeepFlow is built for: making complex work observable and controllable as it flows across people and AI. Our 4D graph explicitly shows concurrency and dependencies in workflows, and we focus on agentic orchestration, sending the right subtask to the right teammate, agent, or model at the right time—while keeping human-in-the-loop control and full auditability of every step. AsyncThink's core idea of learning when to fork work, when to synchronize, and when to stop rhymes with the same coordination problems we visualize and manage in real workflow graphs.
The figure below is a great "mental model" for the paper: it contrasts sequential thinking, naive parallel thinking, and AsyncThink's organizer-driven fork/join structure.
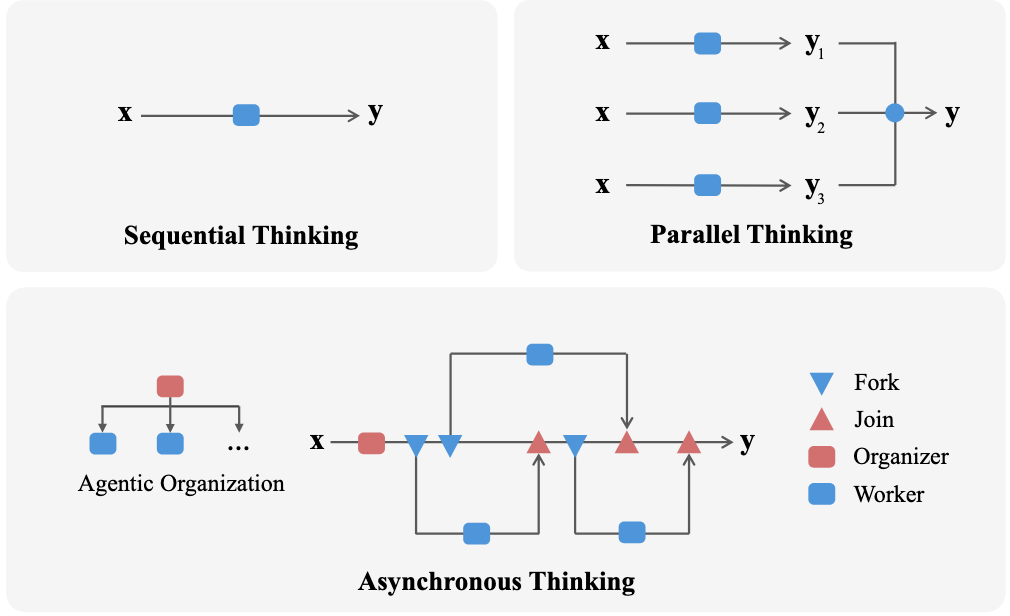
Figure from the paper: Three reasoning styles, one key difference. Sequential thinking is one long chain; parallel thinking runs multiple independent attempts and aggregates at the end; AsyncThink creates a coordinated "fork–join" reasoning graph where an organizer delegates sub-problems to workers and merges them back when useful.
What the paper claims
AsyncThink introduces an organizer–worker thinking protocol implemented entirely in text: the organizer can Think, Fork a sub-query to a worker, Join a worker's return into its own context, and finally Answer. Workers independently solve assigned sub-queries and return concise takeaways.
This pipeline is trained in two stages: format fine-tuning to learn the action syntax, then reinforcement learning to improve both correctness and efficiency.
The key payoff: better accuracy with lower "critical-path" latency, which is the length of the longest dependency chain in the reasoning graph—the part you can’t parallelize away—so it corresponds to what a user actually waits for even if some work happens concurrently. The paper reports 28% lower inference latency than parallel thinking while improving math accuracy, and that the capability generalizes to unseen tasks.
Where the paper gets especially concrete is in the accuracy–latency tradeoff on math reasoning. On AMC-23, AsyncThink reaches 73.3% accuracy at 1459.5 critical-path latency, compared with 72.8% at 2031.4 for the best parallel baseline (Parallel-Thinking-L2K). On AIME-24, AsyncThink matches the best reported accuracy (38.7%) but at 1468.0 latency instead of 2048.0 for the parallel baseline.
The frontier plot below makes the punchline obvious: AsyncThink shifts the curve—better accuracy at the same latency, or the same accuracy with less latency.
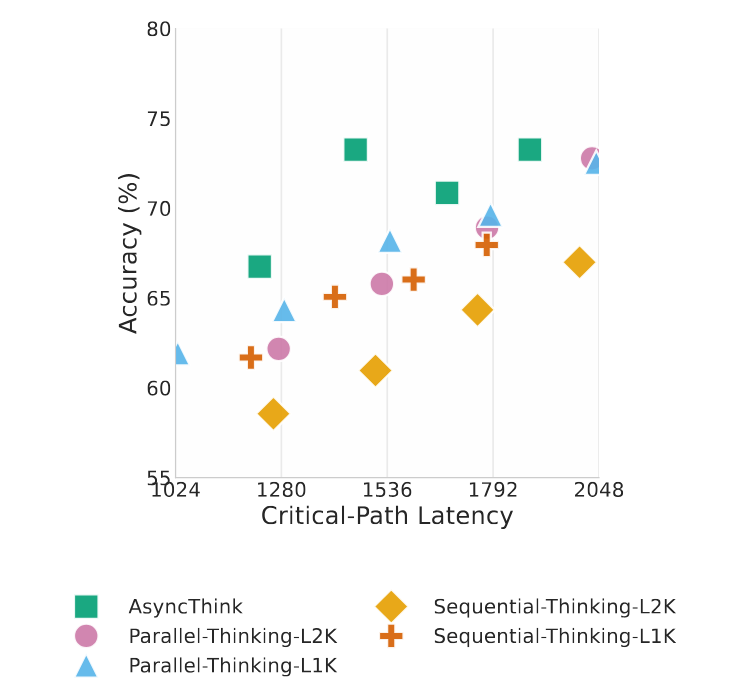
Figure from the paper: Accuracy–latency frontier. AsyncThink achieves higher accuracy at a given critical-path latency (or lower latency at a given accuracy) than sequential and parallel thinking baselines, illustrating the practical benefit of learned fork/join organization.
What we discussed
A few themes kept resurfacing:
- Parallelism shouldn’t be "all-at-once." The really interesting claim here is not "multiple agents help"—we already know that. It’s that the model learns when to branch and when to merge, instead of running N whole attempts and voting at the end.
- Thinking in graphs, not chains. The idea of measuring latency by the critical path helped us talk about agentic reasoning like a workflow DAG: what must happen sequentially vs. what can run concurrently.
- The concurrency reward matters—but can be tricky. The paper uses rewards that combine correctness, format compliance, and a "thinking concurrency" component designed to encourage parallelizable structure while avoiding reward hacking via a threshold. We liked the principle: reward the system for using concurrency well, not just for thinking longer.
- When does forking actually help? We spent time on what good "fork triggers" look like—i.e., when branching is real decomposition versus just exploring multiple avenues—and how that affects generalization beyond math-style tasks.
Why it matters for DeepFlow
DeepFlow is fundamentally about orchestrating work across AI and humans with clear visibility into dependencies. AsyncThink is a helpful lens for these practical reasons:
- Orchestration logic can be treated as something you can train and improve, not just write once: DeepFlow workflows already encode orchestration decisions. AsyncThink reinforces that questions like what to parallelize, when to synchronize, and when to stop are first-class design choices worth measuring and iterating on—not just hard-coding.
- A delegation mindset: the "organizer decides when to ask for help" framing is a useful model for adaptive delegation across agents, tools, and (when needed) humans-in-the-loop.
- More parallelism → more need for traceability: as systems branch and merge more, auditability matters—not just what the answer was, but which branch produced it and what got merged.
Closing reflections
AsyncThink's core bet is that better reasoning isn't just about more tokens or more attempts—it's about coordination: deciding when to delegate, how to merge partial work, and when it's safe to stop.
That matters because real-world systems don't fail only on correctness—they fail on latency budgets, wasted parallel work, and messy aggregation. AsyncThink suggests there's a learnable middle ground between "one long chain" and "run everything in parallel": a model that can organize its own computation like a workflow.
If that idea holds beyond benchmarks, the next step in agentic systems may look less like brute-force parallelism—and more like structured execution: branching only when it helps, merging only when it adds signal, and finishing early when the job is done.
This post is part of DeepFlow's ML Reading Group series, where we share reflections on the latest AI research and its impact on workflow automation.
