

Reinforcement Learning Scaling Laws And The Art Of Predictability

At this week's ML reading group at DeepFlow, we found ourselves talking less about new algorithms and more about something rarer: predictability of RL performance.
If scaling language models is an art guided by smooth power laws, could reinforcement learning (RL) follow a similar rhythm? Or does RL, with its unstable gradients and reward quirks, remain an unpredictable beast?
ScaleRL argues that RL can, in fact, be tamed — and that performance gains follow a surprisingly reliable pattern once you plot them against compute. The result is a practical framework for treating RL training as a measurable investment, not a gamble.
Why this paper caught our attention
Scaling laws have long shaped the way we plan large language model (LLM) training runs, but RL — particularly post-training alignment — has lacked such clarity. ScaleRL fills that gap.
The authors trained models across more than 400,000 GPU-hours, exploring different loss functions, architectures, and training recipes. Their key insight: RL performance over compute follows a sigmoid curve — an S-shaped trajectory that starts slow, rises steadily, and then saturates at a ceiling.
By fitting this curve early in training, they show that it's possible to predict final reward accuracy long before the run finishes.
In one experiment, a fit after just 50% of training (≈50k GPU-hours) correctly forecasted the final performance at 100k GPU-hours, both for an 8B dense model and a 17B mixture-of-experts (MoE) model.
That kind of predictability changes how we think about scaling RL — from trial-and-error to measurable planning.
What the paper claims
The figure below shows how ScaleRL fits a curve to early training and uses it to predict the rest of the run.
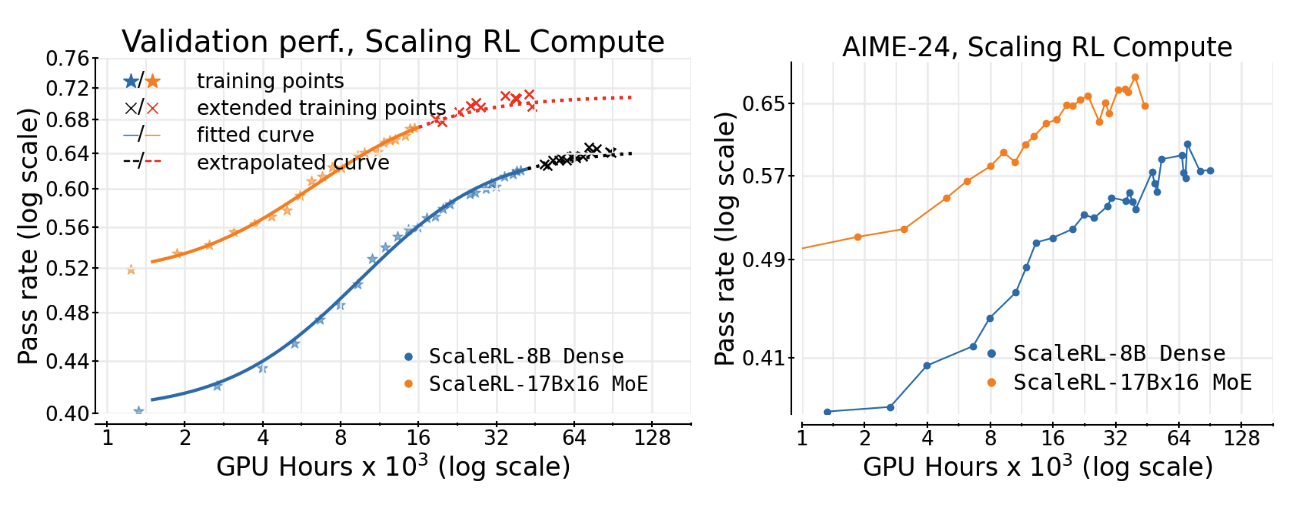
Figure from the paper: ScaleRL's scaling curve. A sigmoid fit made halfway through training accurately forecasts final performance at 100k GPU-hours for both 8B and 17B models, showing that reinforcement learning can, in fact, be predicted.
The curve has three interpretable parameters — the ceiling (A), efficiency (B), and midpoint (Cmid) — describing how fast learning accelerates and where it plateaus. Once fitted, it provides a quantitative way to decide whether adding more compute will pay off.
PipelineRL-8: More throughput, same ceiling
A big source of waste in RL training is idle compute between the actor (which generates data) and the learner (which updates weights).
Traditional setups like PPO-off-policy train in chunks — generating data and then learning from it. In contrast, PipelineRL runs both in parallel, keeping GPUs busy. In Figure 4, both methods reach similar final accuracy (around 0.6 mean@16), but PipelineRL-8 gets there faster — higher efficiency (B) without lowering the ceiling (A). This made it the paper's default recipe for all later experiments.
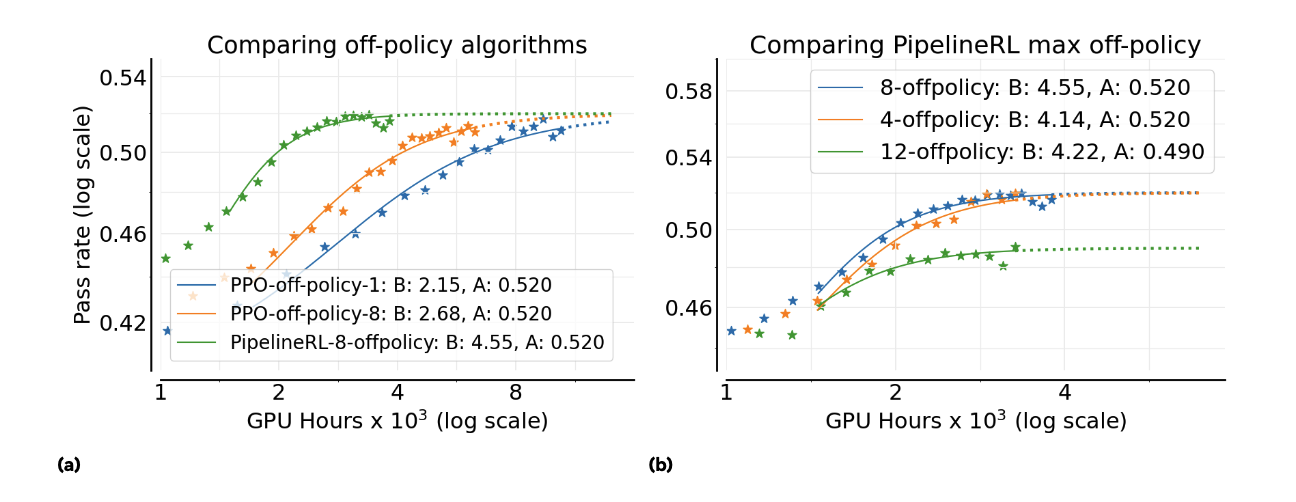
Figure from the paper: (a) PPO-off-policy vs PipelineRL-8 scaling. (b) Varying off-policy depth with PipelineRL. Both reach similar final accuracy, but PipelineRL trains faster and uses compute more efficiently.
Small tweaks, big ceilings
Two small recipe choices made outsized differences:
- Loss function: The authors compared different RL loss objectives — DAPO, CISPO, and GSPO. CISPO (Contrastive Importance-Sampled Policy Optimization) consistently achieved higher late-stage rewards, suggesting better gradient stability.
- Numerical precision: Simply computing the LM-head logits in FP32 (instead of mixed precision) raised the ceiling from ≈0.52 → 0.61. A subtle fix, but one with clear, measurable gains.
Batch size and scaling behavior
Larger batch sizes learn more slowly at first but end higher, while smaller ones learn faster but plateau early; a familiar "tortoise and hare" pattern. Across all experiments, the same sigmoid trend held, suggesting that RL scaling behaves far more consistently than expected.
What we discussed
Our main discussion circled around one theme: recipes don't just scale — they scale differently.
Some tweaks, like PipelineRL or CISPO, steepen the learning curve (better efficiency). Others, like FP32 precision or larger batches, lift the maximum ceiling. Knowing which effect a change has helps engineers choose where to spend compute wisely.
We also liked that the paper makes predictable failure a feature, not a flaw. If a curve shows early on that performance will plateau below target, you can stop the run and redirect resources elsewhere — a practical win for any large-scale training setup.
Why it matters for DeepFlow
DeepFlow's orchestration platform unites AI agents, human operators, and workflow logic within a single 4D graph. Predictability and efficiency are central to how we scale our own systems.
Here's what ScaleRL means for us:
- Forecastable RL runs:
We can integrate ScaleRL-style curve fitting into our internal RL pipelines to predict saturation points. If the curve shows diminishing returns, teams can stop early — a direct compute saver. - Smarter orchestration planning:
Understanding which parameters raise the ceiling (batch size) versus speed up training (off-policy design) helps us budget compute strategically, both for research and for customer-facing workflows.
Beyond direct applications, the broader lesson aligns with DeepFlow's philosophy: observability and control shouldn't stop at runtime. They belong in training too, and ScaleRL offers a blueprint for that.
Closing reflections
ScaleRL reframes reinforcement learning as something you can plan, not just hope for.
Its message is simple but powerful: with a well-fitted curve and a few smart tweaks, RL becomes predictable — and predictability is what turns experimentation into engineering.
For DeepFlow, that lesson extends beyond RL. The more we can forecast and instrument our own systems — from model training to agent orchestration — the closer we get to workflows that scale with purpose, not guesswork.
This post is part of DeepFlow's ML Reading Group series, where we share reflections on the latest AI research and its impact on workflow automation.
