

Tracing faults in agentic systems

At this week's reading group, we asked a painfully practical question: when a team of LLM agents drop the ball, how do you figure out which step actually caused the failure? Reading 16k-token logs is nobody's idea of fun. This paper proposes a way to let statistics do the sifting.
Why this paper caught our attention
FAMAS introduces a spectrum-analysis approach to failure attribution in LLM-powered multi-agent systems (MAS). Rather than "ask an LLM to judge the log," it replays the same task multiple times, then ranks steps in the original failed run by how strongly they correlate with failure across replays.
In real workflows, agents call tools, hand off state, and retry. Pinpointing the single decisive error, i.e. the action that puts the system into an unrecoverable state, can turn a day of spelunking into a targeted fix. This is exactly the reliability work we care about for multi-agent orchestration. Our discussion circled around moving from "post-hoc stories" to data-backed blame assignment.
What the paper claims
The figure below shows that replaying the same task yields both passes and fails - exactly the signal that FAMAS exploits.
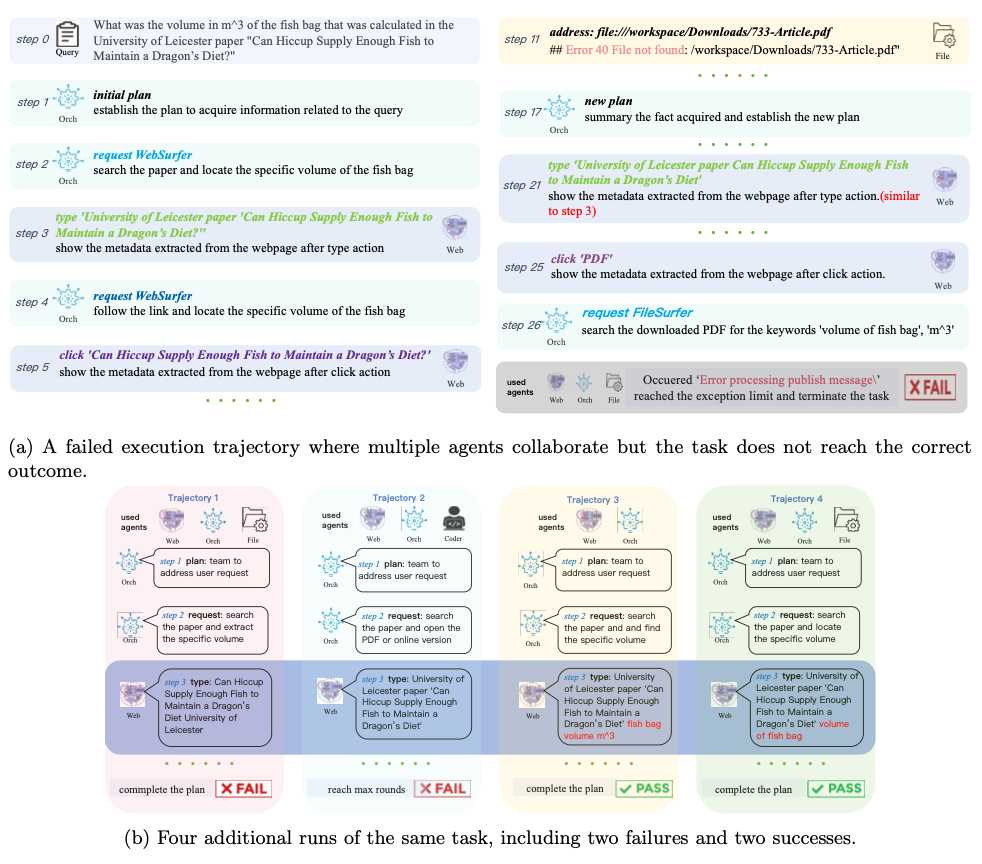
Figure from paper: Execution trajectories of a real-world task. A failed trace (a) and four replays (b) of the same GAIA task using the multi-agent system MagenticOne—two fails and two passes—show why repeated runs of the same task provide the signal FAMAS uses.
FAMAS borrows Spectrum-Based Fault Localization (SBFL) from software debugging: compare what appears in successful vs. failed executions; actions that consistently co-occur with failures get higher suspiciousness.
FAMAS adapts SBFL to MAS logs by:
- abstracting raw logs into agent–action–state triples via an LLM and clustering semantically equivalent steps,
- computing a suspiciousness score per triple using a tailored formula that blends:
- cross-run failure correlation (Kulczynski2 with a frequency-decay factor λ),
- local repetition in the failed run (α), and
- how core that action is to the agent (β, γ).
- cross-run failure correlation (Kulczynski2 with a frequency-decay factor λ),
The final score multiplies these parts to rank the decisive error.
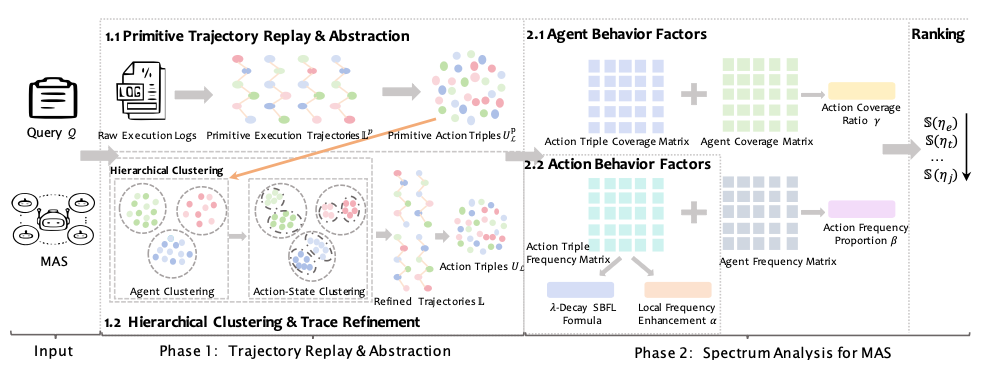
Figure from the paper: FAMAS pipeline. Replaying the task builds a behavioral spectrum; suspiciousness blends cross-run failure correlation (Kulczynski2 with decay λ), local repetition in the failed run (α), and agent-behavior factors (β,γ) to rank the decisive step.
Evaluation: On the Who&When benchmark (184 failure logs from 127 MAS), FAMAS achieves 57.61% agent-level and 29.35% action-level Top-1 attribution, the state of the art against twelve baselines (random, LLM-judge variants, classic SBFL formulas).
Settings & sensitivity: Default parameters are k = 20 replays and λ = 0.9; performance peaks for λ in roughly 0.9–0.95. FAMAS is stronger on complex, handcrafted logs (41.38% action-level) than on short, algorithmic ones (23.81%), likely because longer traces provide a richer "spectrum."
Runtime: End-to-end attribution averages ~105 minutes (most of it in replay and abstraction), while the spectrum math itself runs in under a minute.
What we discussed (and debated)
- Logs vs. judges: Prior "LLM-as-a-judge" methods underperform on action-level attribution. We liked that FAMAS avoids relying on content semantics and instead uses occurrence patterns across runs.
- Clustering matters: Using an LLM to semantically cluster near-duplicate actions is crucial; without it, string-level mismatches would erase signal.
- Practicality: Replay costs are real, but the trade-off is a repeatable diagnosis rather than brittle prompt-engineering for judges.
Why it's interesting for DeepFlow
This resonates naturally with DeepFlow's emphasis on auditability and human↔AI hand-offs in orchestrated workflows. We already capture detailed logs of every step in a workflow graph, and FAMAS proposes a way to turn those logs into actionable "blame heatmaps."
Where it could help:
- Incident triage: For flaky multi-agent runs, compute suspiciousness over recent replays to highlight the decisive action and the responsible agent or tool node in the 4D workflow view.
- Regression hunting: After a prompt or policy update, re-execute a small suite (say k ≈ 10) and flag steps whose suspiciousness spikes—an early-warning signal before customers feel it.
- Post-mortems with less drama: Attach a one-page "spectrum card" to each failed ticket: top suspected action, agent, and links to exemplar failing vs. passing traces.
That said, FAMAS needs replays of the same task, and the benefit grows with log richness. On very short, highly stochastic flows, the signal will be weaker, so we’d treat this as a debugging aid, not a silver bullet.
Closing reflections
Debugging agentic systems shouldn't rely on vibes. FAMAS gives a statistical approach: if a step keeps showing up where failures cluster and rarely where things work, start there. It's not the end of the story (we still need root-cause fixes), but it's a faster way to find error-inducing states for further debugging.
This post is part of DeepFlow's ML Reading Group series, where we share reflections on the latest AI research and its impact on workflow automation.
